In a recent article, I wrote about using Langchain and FAISS to build a RAG system. FAISS, however, is in memory and not scalable when you want to update the training data constantly in real-time.
Qdrant is a great alternative to FAISS. In this article, we will look at building a basic similarity search using Langchain and Qdrant.
What is Qdrant?
In the world of machine learning these days, it's a common practice to vectorize text and store it in a backend DB, unfortunately, most modern databases such as MySQL are not designed to store vector embeddings, although things move fast in the machine learning world and support is getting better, vectors are not yet a first-class citizen for RDBMS type databases.
Qdrant is a modern database that's optimized for storing unstructured data, more especially vector embeddings. Besides being a vector store, you can also use Qdrant as a search engine, it lacks features such as faceting but still is pretty useful on longtail phrase type searches.
Take for example: "Please suggest a high-end gaming machine with lots of RAM and a good graphics card ", a regular keyword search might return no results or poor results.
I tried this on Amazon.com and got weird results for: RAM, mini PCs, and socks 😂:
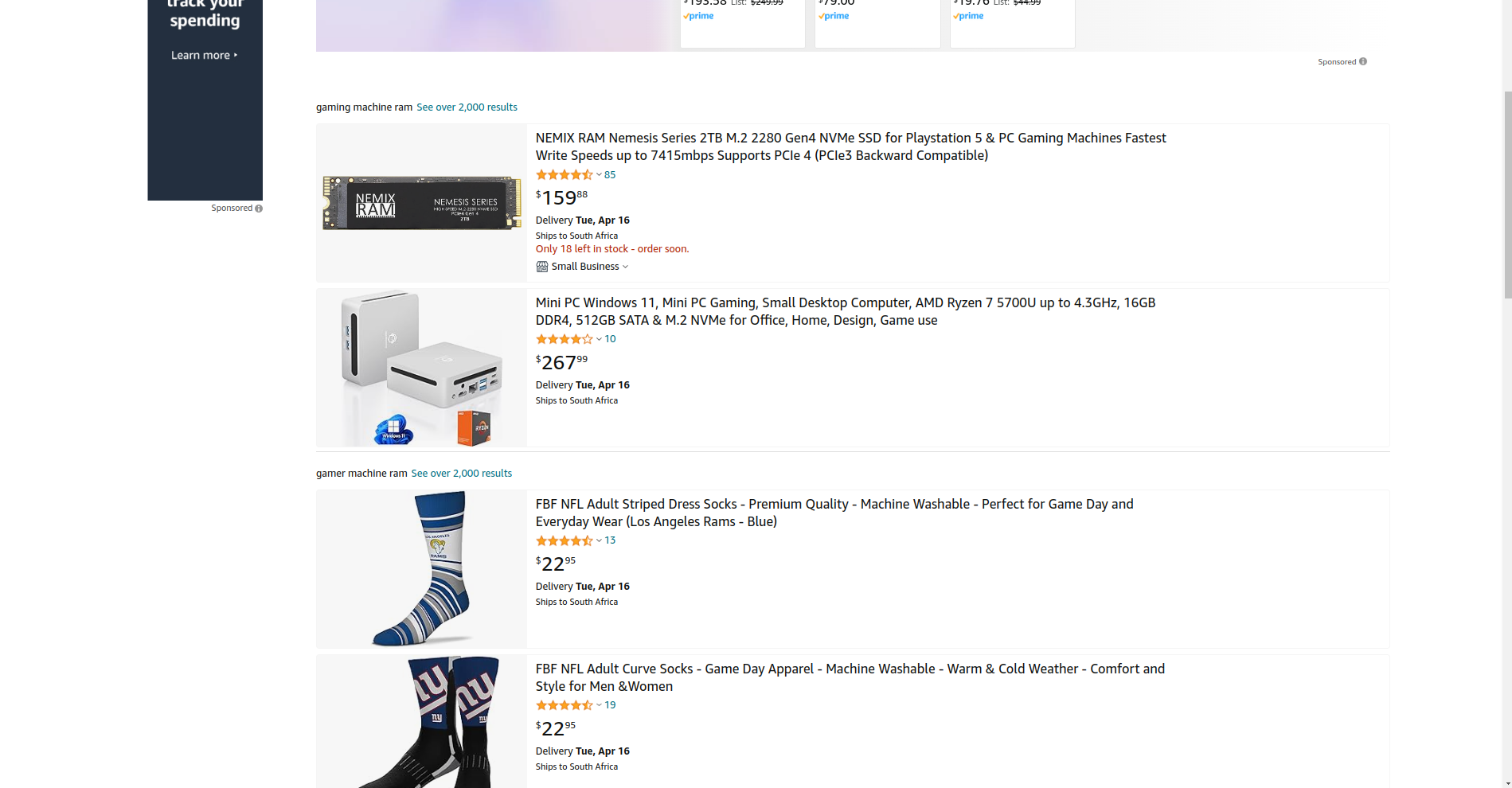
Naturally, this confuses a keyword-based search engine because it's looking for specific keywords or their synonyms. On Qdrant, you can most probably find "gaming laptops" for the same above search. Since the vector-based search also stores "meaning" and uses algorithms such as "kNN" with cosine similarity to better understand the searcher's intent.
If you don't know what vector embeddings are: they are basically a numerical representation of text, that machine learning models can use to perform math calculations, in-order to determine meaning and relationships between words and phrases. Qdrant's website provides a more in depth article on this subject as well, you can learn more here.
Setting up Qdrant
Similar to most NoSQL databases, Qdrant uses the concept of "collections". Essentially a collection is a unique grouping of documents, similar to an SQL table.
The easiest way to get started with Qdrant, is to use the docker image:
docker run -dit -p 6333:6333 qdrant/qdrant
You should now be able to view the web dashboard by visiting the following link: http://127.0.0.1:6333/dashboard
Before we get to the code, you will need to install a few pip packages:
pip install langchain
pip install qdrant_client
pip install langchain-community
pip install langchain-openai
Setting up our schema:
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams
from langchain.embeddings import OpenAIEmbeddings
from langchain_community.vectorstores import Qdrant
embeddings = OpenAIEmbeddings()
client = QdrantClient('http://127.0.0.1:6333')
langchain_qdrant_store = Qdrant(
embeddings=embeddings,
client=client,
collection_name="products"
)
client.create_collection(
collection_name="products",
vectors_config=VectorParams(size=1536, distance=Distance.COSINE),
)
When you run the above, it should create a collection named: "products" with one field that will house our vector embedding. For the purposes of this article and to keep things simple, I am just storing the vector embeddings and no other extra meta information.
You can most certainly, store more information using "payloads" if needed. Learn more about payloads here.
Storing documents in the collection
Storing documents in the collection is fairly straightforward when using the "OpenAIEmbeddings" and Langchain Documents. Langchain will automatically take care of the complexity of querying OpenAI and generating the vector embeddings.
So basically all you need to do, in order to index a document in Qdrant is as follows:
from langchain.docstore.document import Document
doc = Document(page_content="Some text data here")
langchain_qdrant_store.add_documents([doc])
If you want to store documents like PDF’s, here’s an open-source project I built some time ago that provides an example: kevincoder-co-za/ragable
Finding similar documents
To perform a KNN search we simply need to do the following:
documents = langchain_qdrant_store.similarity_search("Some search term")
The above will return a list of "Langchain documents", which you can pass on to an LLM or process further just like you would any other Python object in your application.
Using the Qdrant store as a retriever
Lanchain is awesome and can simplify the process of passing on this information to an LLM for further reasoning, see the example below:
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo-0125", temperature=0)
chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=langchain_qdrant_store.as_retriever()
)
print(chain({"query": question}))
Whenever you pass a question to the LLM, it will automatically query Qdrant for similar documents and then determine its response accordingly based on that context data.
This is quite powerful and is known as "RAG" (retrieval-augmented generation**).** Remember with ChatGPT and other such models, it's often possible for the LLM to hallucinate or provide a response that may be correct but not as in-depth as you may like.
With RAG, you are providing the context data and can scope the LLM to only respond based on the data you provide, this reduces the model's likelihood to hallucinate, and you can enforce an "I don't know" rule or something to that effect when it cannot answer the question effectively.
What can I build with this kind of system?
Some common use cases include:
A summarization tool. You can vectorize hundreds or thousands of documents into Qdrant and then have the LLM summarize and answer questions based on that data. This is useful in various business applications: such as training, onboarding, customer support, and so forth.
Insights tool. Ingest large amounts of statistics and then build an interface with various charts to predict trends and understand your data better. Crime intelligence is a good example.
Suggestion engine. A great use case would be e-commerce, the chatbot can help users with their purchases by providing more information and suggesting other products that may go well together and so forth.
Similarity search. You don't need a full RAG for this, since it'll be slow and use lots of resources if you have a high volume of searches. Qdrant alone is sufficient though using the "similarity_search" function.
These are just a handful of suggestions, I am sure there are loads more interesting applications that can be built using this platform.
What are the disadvantages of using Qdrant?
One of the major pain points with Qdrant is how the querying engine works, it’s similar to NoSQL but very basic and cumbersome to work with if you need to do some advanced filtering like you would in SQL:
where city="Cape Town" and price >= 500
In Qdrant:
POST /collections/{collection_name}/points/search
{
"filter": {
"must": [
{
"key": "city",
"match": {
"value": "Cape Town"
}
},
{
"key": "price",
"range": {
"gte": 500
}
}
]
}
}
As you can see, it’s so much more verbose and cumbersome to work with versus just plain old SQL, however, this is not a problem usually because 90% of the time you basically just use Qdrant for the similarity search and then can get back a list of IDs or something to identify your data and then use those to query your SQL backend.
Another issue is that while their documentation is fairly okay, it’s still very new thus there are very limited resources and you have to dig into the docs quite a bit to find what you looking for(although these days we just ask Claude right?).





